Veo 3 and the Rise of Multimodal AI
DeepMind’s Veo 3 generates full-resolution videos with synchronized audio from text prompts, marking a major leap in multimodal generative AI.
Supporting NovaLuna’s secure, GPT-powered automation that streamlines enterprise workflows.

Welcome to the Age of Seamless Generative Storytelling
The year is 2025, and the generative AI landscape is no longer dominated by models that can only write, speak, or draw. We’ve now entered a fully multimodal era—where AI not only understands language but brings it to life through synchronized video and audio creation.
At the forefront is Google DeepMind’s Veo 3, a groundbreaking system capable of turning text prompts into cinematic-quality videos with realistic audio, including dialogue, ambient sound, and music—all aligned, all generated from scratch.
What Makes Veo 3 a Milestone?
Here’s what sets Veo 3 apart in the current AI landscape:
- Text-to-Film Capabilities: From a single sentence, Veo 3 produces a cohesive visual and audio narrative.
- Full-Resolution Output: Supports up to 4K video generation.
- Synchronized Audio Engine: Combines speech synthesis, ambient audio generation, and music production.
- Scene-Aware Generation: Maintains continuity across frames, voices, and transitions.
“We’ve gone from describing a scene to watching it unfold—complete with soundtrack,” said DeepMind CEO Demis Hassabis.
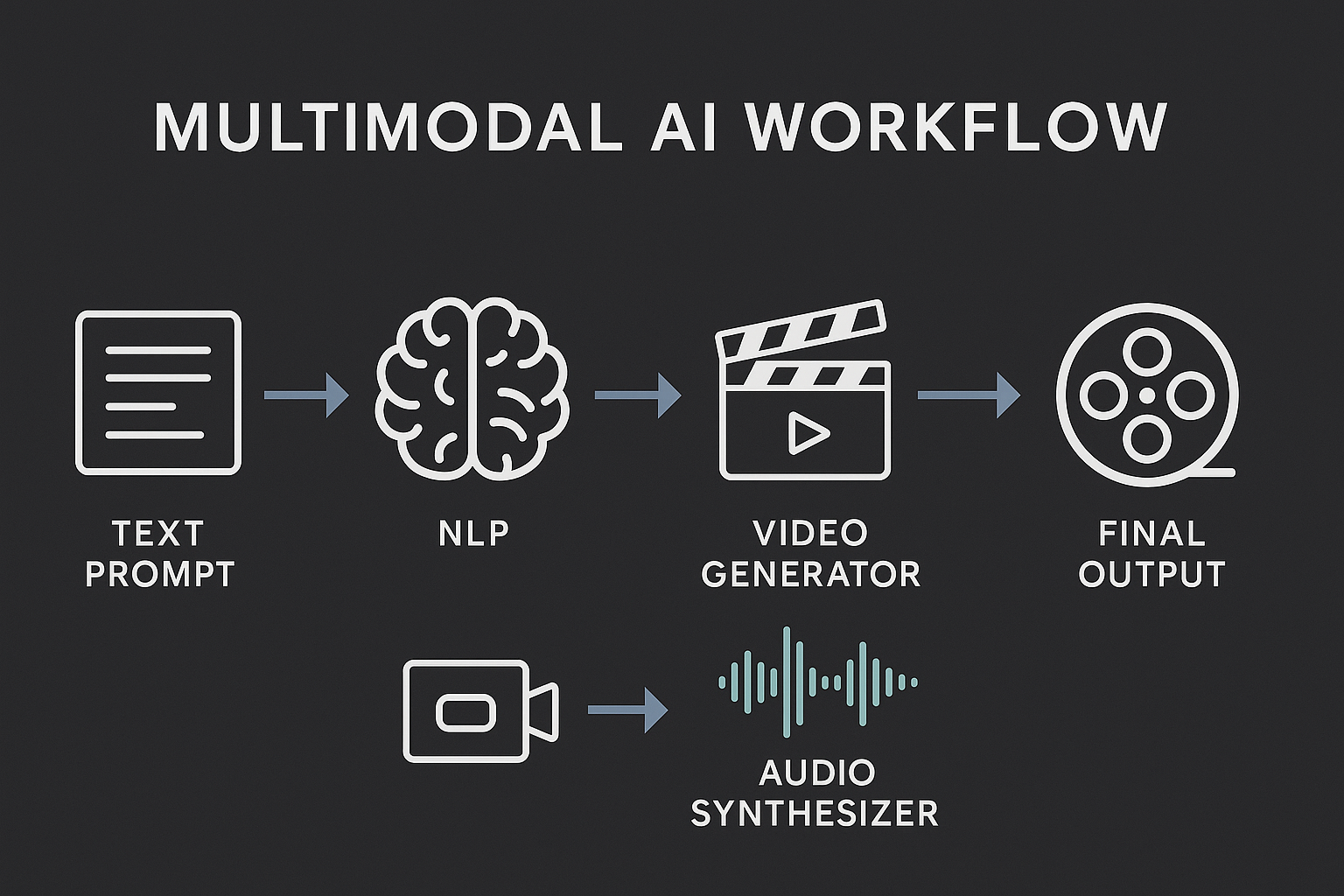
Why Multimodal AI Matters for the Enterprise
The rise of multimodal generative AI like Veo 3 isn't just a creative breakthrough—it has deep implications for enterprise tools, content pipelines, and customer engagement.
Here’s what businesses need to know:
End-to-End Content Automation
- Marketing teams can auto-generate tailored video campaigns with voiceovers.
- Training modules can be produced in minutes with human-like narration and scenarios.
- AI agents can generate explainer content, dynamically, based on user queries.
Personalized Experiences at Scale
- Dynamic product demos tailored per customer segment.
- In-app storytelling that responds to user behavior.
- Brand narratives generated in multiple languages and voices.
Ethical and Regulatory Considerations
- Misinformation risk from realistic synthetic media.
- Need for watermarking, traceability, and verification layers.
- Growing demand for enterprise-grade governance tools to manage AI outputs.
What's Next for Multimodal Systems?
Veo 3 may be the star of 2025, but the wave is just beginning. Companies like OpenAI, Runway, and Meta are racing to integrate text, video, and voice into interactive agent systems. Expect the next evolution to include:
- Real-time prompt-to-video interfaces
- Interactive multimodal agents
- Full-scene rendering pipelines for gaming and VR
At NovaLuna, we see this as a turning point. The convergence of text, vision, and voice isn’t just a technical upgrade—it’s the foundation of future enterprise intelligence.
Closing Thought
We’re rapidly moving from "prompt engineering" to prompt directing—where anyone can shape audio-visual experiences as easily as writing a paragraph. With Veo 3, multimodal generative AI becomes not just a research dream, but a practical toolkit for businesses to build richer, faster, and more human-like digital experiences.
Subscribe to our newsletter today
Get the latest insights on Generative AI, automation breakthroughs, and enterprise-ready LLM tools—delivered straight to your inbox.